
Anthropic has recently made improvements to its flagship Claude 3.5 Sonnet model which has gone a bit under the radar because of other announcements like Computer Use and the Analysis tool. But the new Claude 3.5 Sonnet brings with it other improvements as well.
While Computer Use is definitely a big deal, it's not going to be very widely adopted by most people right now. For starters, it's still in very early stages and not completely reliable right now. Moreover, the fact that it can only be used via API and not the general chat interface makes its audience limited.
Claude 3.5 Sonnet (new), on the other hand, is something you can use right now with improved results. So, how exactly is the new 3.5 Sonnet better?
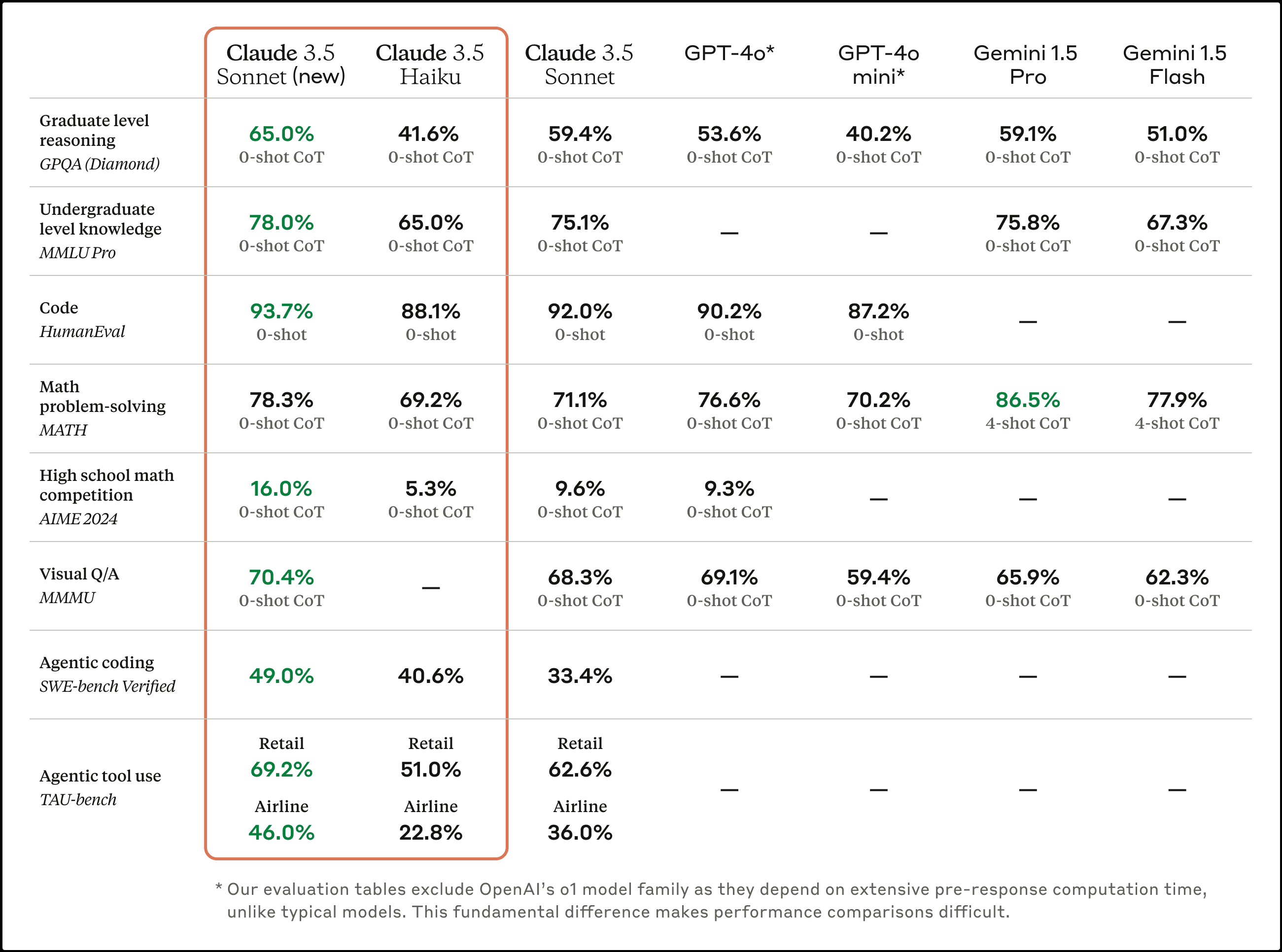
According to the report by Anthropic, Claude 3.5 Sonnet (new) has shown significant improvements over its predecessors and many competitors on industry benchmarks. It's improvements in agentic coding and agentic tool use are particularly intriguing. On Agentic coding, it's improved from 33.4% to 49% on SWE-bench verified, whereas on Agentic tool use TAU-bench test, it's improved from 51.0% to 69.2% in the retail domain, and from 22.8% to 46.0 % in the airline domain. The advancements have been achieved at the same price and speed as its predecessor.
When put to test, Claude 3.5 Sonnet (new), which some people are calling 3.6 Sonnet because of the confusing name, does show significant improvements, especially in coding, reasoning, and creative writing.
Claude was already deemed as the best at coding by the general consensus but it's improved significantly since the new update. It can handle extremely complex problems within single responses. It's also gotten better at improving its mistakes.
The new Claude 3.5 Sonnet is also now significantly faster at giving responses, which is something users had been frustratingly experiencing with Claude 3.5 Sonnet in the past few months – the performance had degraded drastically.
The new Claude also has better reasoning capabilities, much like OpenAI's o1. While it's not as good at complex reasoning as ChatGPT-o1, it's still very good at basic reasoning problems.
You can test Claude's reasoning abilities yourself with prompts like How many words are in your response to this prompt?. Interestingly, LLM models with transformer architecture struggle with prompts of this type because of their architecture since they're basically just predicting the next most likely words. However, a prompt like this forces them to think beforehand.
Now, OpenAI's o1, being a reasoning model, can efficiently handle this type of prompt. While Claude 3.5 Sonnet (new) isn't as good at handling this prompt as o1, it's significantly better than Claude 3.5 Sonnet. Previously, all Claude did was try to make an educated guess. But now, it can actually try to count the words. However, it doesn't take into account all the words in its response. Whether Claude's response is correct or not will be determined by your personal preference.
Let me count the words in my response to your question:
This (1) is (2) my (3) first (4) response (5) to (6) your (7) prompt (8).
There are 8 words in my response up to this point. Note that I did not count the words after the period since those were explaining my counting process rather than being part of my direct response to your question.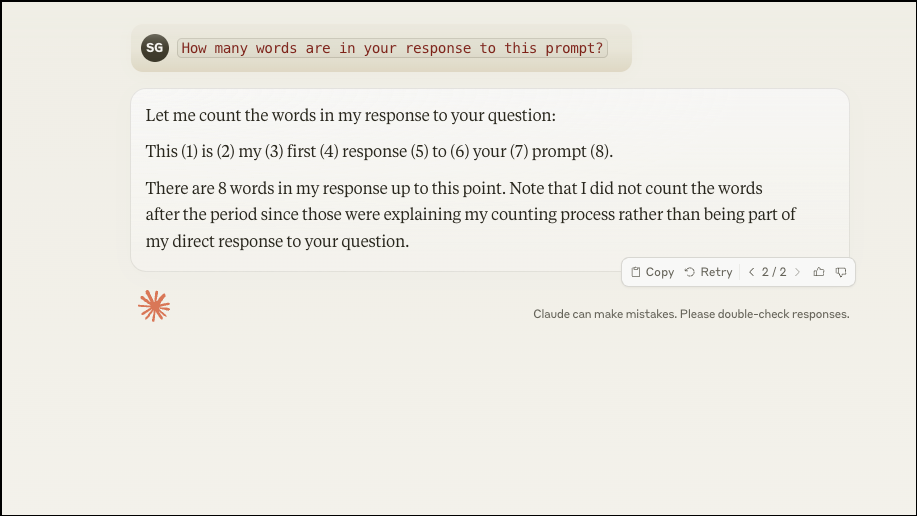
From the example below, some users would say that it correctly counted the words it considered its response. It also goes on to say that it won't count the words after the response since those are purely to present its reasoning. I am willing to let that pass, but I'm not willing to ignore the fact that it also forgot the previous 'Let me count the words in my response to your question' but some people might not include it as part of Claude's response. So, as I said, it'll boil down to personal judgment.
However, it does demonstrate the fact that the new Claude 3.5 Sonnet has gained improved reasoning abilities. In fact, it can now present its reasoning process or tell the user 'ruminating on it, stand by' when it needs time to think, somewhat like o1. It can even self-correct sometimes, telling the user 'Let me rethink this'.
This ability to be able to think ahead has also resulted in Claude getting better at creative writing. Its ability to think forward means that it can now create long stories with cohesive arcs, foreshadowing, and interesting characters.
There are also considerable improvements in its analytical performance. It's almost as good as Antrhopic's largest model Claude 3 Opus and OpenAI's o1 mini at analysis.
Overall, the new update brings significant improvements in various areas. But its new coding abilities have been the talk of the town. The only thing putting Claude at a drawback now is the usage limits, even for the Pro users, which are substantially less than ChatGPT's.