When the first AI-generated video was released, nobody could have guessed that video-generating AI tools would come so far in such a short period. However, today we have countless platforms that allow users to generate high-quality, incredibly detailed videos, such as Synthesia and Luma AI’s Dream Machine. That said, there are still a few challenges that prevent these tools from going mainstream.
And the biggest one perhaps is the audio generation process. While most video-generating platforms can produce good-quality videos, they are mostly silent videos without any audio. Even if there is audio, it is usually added separately and falls short of user expectations.
For instance, if you visit Luma AI’s Dream Machine page, you can see some very impressive videos but the sound that accompanies them is quite generic and of low quality. But that may be about to change with Google’s new video-to-audio (V2A) technology.
This promises to bring good-quality audio generation for videos to the masses, meaning it may finally allow you to produce AI-generated movies with proper soundtracks and audio, surpassing all AI-generated videos that are currently being produced.
AI-generated audio for a guitar.
What is Google DeepMind’s Video-to-Audio Research?
Video-to-Audio (V2A) technology developed by Google’s DeepMind is designed to create soundtracks for AI-generated videos. This technology makes it possible to generate videos and audio simultaneously by combining natural language prompts with video pixels to generate sounds for whatever actions are taking place in the video.
This technology can be paired with AI models used to generate videos, like Veo, and can help create realistic dialogues and sound effects along with dramatic scores that match the video. More importantly, the new V2A technology is not just limited to videos generated using AI, but can also be used to generate soundtracks for videos produced in the traditional manner. Thus, you can use it for silent films, archival material, and more.
The V2A technology allows users to generate unlimited soundtracks for videos and even use positive and negative prompts to guide the sound generation process and get the required sounds easily. This also allows more flexibility, so you can experiment with various outputs and find what is best for a particular video.
An audio sample of a jellyfish pulsating underwater.
How does the V2A technology work?
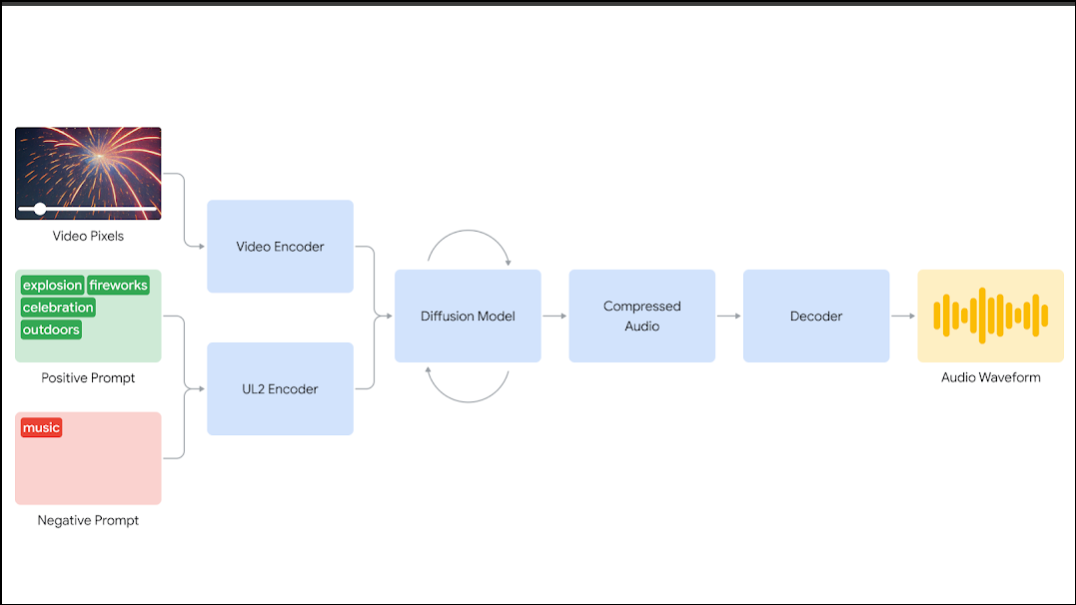
According to Google, the company experimented with diffusion-based and autoregressive techniques and found the former to be most suitable for sound production. It results in highly realistic sounds and works by encoding the video into a compressed format.
After that, the diffusion model is used to separate random noise from the video by relying on natural language prompts and the video. The prompts help generate realistic audio that is perfectly synchronized with the video. This is followed by decoding the audio after which it is converted into an audio waveform and merged with the video.
Google’s DeepMind provided more information to train the AI because of which users can guide the audio-generation process towards the required sounds and allows the platform to produce higher-quality audio. Such information included spoken dialogue transcripts and detailed sound descriptions with AI-generated annotations.
Being trained on such information, the V2A technology can associate different visual scenes with specific audio events.
What’s on the horizon?
DeepMind’s V2A technology performs much better than other V2A solutions since it does not always require a text prompt and can understand video pixels. The sound output also does not need to be manually aligned with the video. However, there are still certain limitations of the technology, which Google aims to overcome with further research.
For instance, the quality of the audio generated depends on the quality of the video used as input. If there are distortions or artifacts in the video, the AI model fails to understand those since they are not included in its training, ultimately resulting in reduced audio quality.
Additionally, for videos that have human speech, the company is working to improve lip synchronization. The V2A technology tries to generate speech using the input transcripts and then align it with the lip movements of the characters in the video. However, if the video does not rely on transcripts, there is a mismatch between the audio and the lip movements.
With better audio generation capabilities, AI models will be able to generate videos that not only look impressive but also sound great. Google is also integrating its V2A technology with SynthID, which watermarks all content generated using AI. This can help prevent it from being misused, ensuring complete safety.
In addition, the company says it will test its V2A technology rigorously before releasing it to the public. So far, from what Google has showcased and promised for the future, this technology is shaping up to be a major advancement in audio generation for AI-generated videos.