Duplicate files can clutter your Linux system and consume valuable disk space. Whether it’s multiple copies of the same document, images, or downloads, identifying and removing these duplicates can help optimize your storage. One efficient tool for accomplishing this task is the fdupes command-line utility.
Using ‘fdupes’ to find duplicate files in Linux
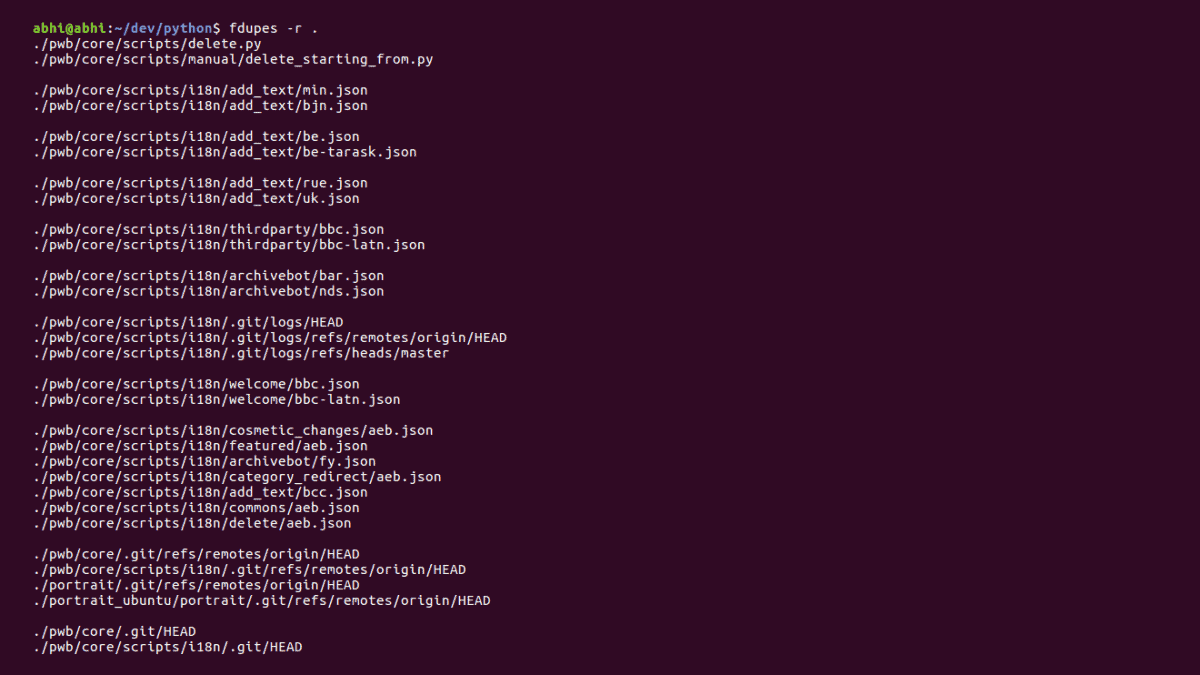
The fdupes utility scans directories to find duplicate files by comparing file sizes and MD5 signatures. To locate duplicates in a specific directory, open your terminal and run:
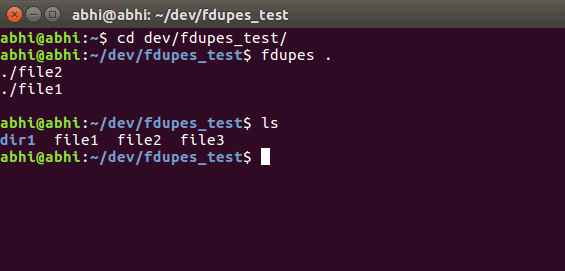
fdupes <directory_path>Alternatively, navigate to the desired directory using the cd command and execute fdupes . (where . represents the current directory).
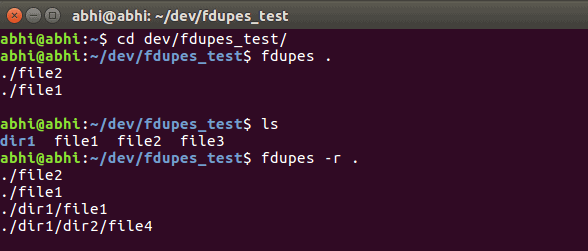
By default, fdupes checks only the specified directory. If you want to search for duplicates within subdirectories as well, use the recursive flag -r:
fdupes -r <directory_path>This command will traverse all subdirectories within the specified path, ensuring that duplicates are found throughout the entire directory tree.
Removing duplicate files
Once you’ve identified duplicate files, you can remove them using the rm command. For example:
rm <filename>This method is straightforward but can become tedious if you’re dealing with a large number of duplicates.
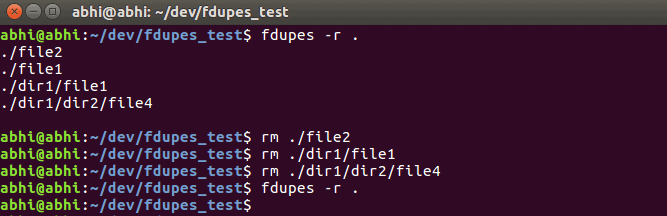
-d option with fdupes. This option prompts you to select which file to keep from each set of duplicates and deletes the rest:fdupes -d <directory_path>You’ll be presented with a prompt to choose the file you wish to retain.
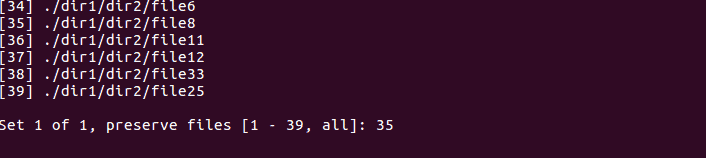

-d option with -N:fdupes -dN <directory_path>This command will delete all duplicates except the first one listed, making the process faster for large numbers of files.
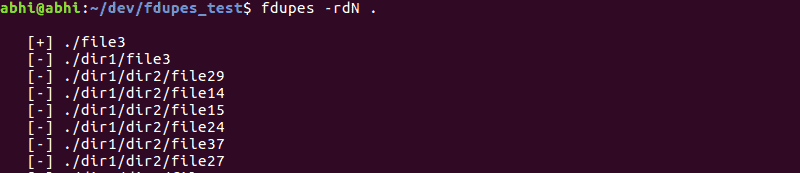
fdupes -rdN <directory_path>This command searches all subdirectories recursively and removes duplicates without prompting, keeping the first instance of each file.
Be cautious when deleting files and ensure that you’re not removing important data. It’s a good practice to back up your files before performing bulk operations.
By effectively using fdupes, you can clean up your Linux system and free up valuable disk space occupied by duplicate files.